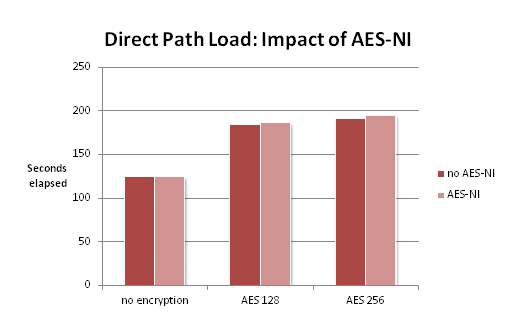
This is not really a technical blog post, it’s an invitation to discuss something. The “something” is what Tony Hasler calls “The Strategic Direction for the CBO”.
Short time ago I started reading his – very much worth reading, very entertaining, too – book on “Expert Oracle SQL”, where without much ado he says, regarding that direction:
Despite the concerns about predictability that customers started raising from the outset and continue to raise today, the strategic direction of the CBO continues to be based on adaptability. Features like dynamic sampling and bind variable peeking started to appear. When 11g arrived it became very clear that the CBO team was looking towards ever more adaptable and ever less predictable behaviors. The signals came in the form of Adaptive Cursor Sharing in 11gR1 and Cardinality Feedback in 11gR2. […] As if this wasn’t bad enough, 12cR1 introduced Adaptive Execution Plans. This feature might result in the execution plan of a statement changing in mid-flight! We don’t want these features!
(See below for a longer quotation, providing more context).
I found this very interesting – normally what you see is people getting annoyed with / frustrated by / furious over
- the bugs accompanying these new features,
- those execution plan changes that are (1) for the worse and (2) get noticed by users (or monitoring systems),
and the new features are getting disabled, at a varying granularity, after a varying amount of analysis/troubleshooting.
(As of today, what percentage of systems upgraded to 12c might be running with optimizer_adaptive_features turned off?).
But this is not about bugs or even how well it works, but about the “principle”. Assume they worked fine, performance was for the better most all the time – how would you like these optimizer self-tuning features?
Here is the Tony Hasler citation again, the complete paragraph this time:
One of the key things about the old Rule-Based Optimizer (RBO) was that the same statement resulted in the same execution plan every time. The CBO, on the other hand, is designed to be adaptable. The CBO tries to get the optimal execution plan each and every time, and if the object statistics suggest that the data has changed then the CBO will quite happily consider a new execution plan.
Despite the concerns about predictability that customers started raising from the outset and continue to raise today, the strategic direction of the CBO continues to be based on adaptability. Features like dynamic sampling and bind variable peeking started to appear. When 11g arrived it became very clear that the CBO team was looking towards ever more adaptable and ever less predictable behaviors. The signals came in the form of Adaptive Cursor Sharing in 11gR1 and Cardinality Feedback in 11gR2. Both Adaptive Cursor Sharing and Cardinality Feedback can result in the execution plan selected for the first execution of a statement being “upgraded” for the second and subsequent executions, even with no change to object statistics! Usually, these changes are for the better, but there are no guarantees.
As if this wasn’t bad enough, 12cR1 introduced Adaptive Execution Plans. This feature might result in the execution plan of a statement changing in mid-flight! We don’t want these features!
– On a test system we don’t want these features because they might mask problems that will impact our production service.
– On a production system we don’t want these features because the execution plans that we have tested are satisfactory, whatever the CBO thinks; we don’t want to risk using an untested plan that might cause performance to degrade.
With the above argumentation, convincing though it sounds, I have two concerns, which in the end are closely interrelated.
First, the “real world” one. There are, of course, many real worlds, but in how many of them is it that the teams of software developers and DBAs, collaborating closely, after thorough, institutionalized testing on the integration systems, can say: Our new code introduced those new execution plans, they are good (or even the best possible), we can safely release our code in production?
One real world I know is where developers develop, and DBAs are busy patching, upgrading databases, working around necessary OS upgrades, providing test systems, and ex- and importing data – only dealing with SQL performance if and when problems arise.
There is this section in the book about a Connor McDonald presentation culminating in
Of course the fictitious execution plan changed was caused by an explicitly run job to gather statistics. No authorization, no impact analysis, no testing, nothing. Connor asked the perfectly reasonable question as to why IT organizations routinely precipitate untested execution plan changes on their database systems while at the same time placing most other types of changes under the highest scrutiny. It seemed to Connor that that the world had gone mad. I agree!
(I told you the book was fun to read.) Now of course the world is mad, but it’s easy to understand the human and organizational factors leading to this special thing. Colors, phrasings, menus on a website are more tangible than execution plans, for one … But that’s another discussion.
So in a practical way, I imagine there’s an idea of easing the DBA’s job because anyway, her job is complex, and getting more complex – in an infrastructure way – all the time (think of the whole Big Data integration topic coming up).
So that leads to the second point. If the intention is to ease the DBA’s job, instead of making it more difficult, introducing problems etc., then adaptivity, or machine learning, sounds like a good idea. With supervised learning, me the DBA, I have analyzed a statement, know the best solution and tell the optimizer how to run it. With unsupervised learning, the optimizer finds out itself.
If we agree that a self-learning optimizer may be a good thing, the question is good are its methods/algorithms? Not in the way of “are they buggy”, but are they, in principle, good techniques that, when bugs have been removed, fulfill their purposes?
Many of the features concerned, and mentioned by Tony Hasler, are based on feedback loops. (That’s the reason for the cybernetic in the post’s title). Being based on feedback loops can mean one of two things here:
- The feedback occurs after execution is complete. This means there was at least one bad execution. (In practice there may have been more). This is the case for Adaptive Cursor Sharing and Cardinality Feedback.
- The feedback occurs mid-execution, as with 12c Adaptive Plans.
With the second form, in principle (again, bugs aside), I don’t have an issue. Join cardinality estimation is intrinsically difficult (just read up on Jonathan Lewis’ blog for that) – now you could either try to find a better generic, one-fits-all-and-handles-every-case algorithm, or you approach the question from another side – such as a control mechanism like the STATISTICS_COLLECTOR rowsource.
As for the first form, you (here meaning the software vendor, i.e., Oracle) could do several things to make it better.
- Re-engineer the underlying algorithm so that fewer failures are needed before the good plan is found.
- Persist the results, so we don’t start again from zero after the information (the cursor) is flushed from the shared pool.
- Ideally, not even a single failure were needed – this is the same as conversion to the second form.
Now for improving the algorithms, this is I guess what’s happening between releases (I don’t have a testcase available, but I’d assume it could be shown for e.g. Adaptive Cursor Sharing between 11.1 and 12.1); for persisting results, look at the evolution from 11.1 cardinality feedback to 12.1 inclusion of that information (now renamed to “statistics feedback”) in SQL Plan directives; for converting to an in-flight algorithm, this may be feasible or not. If it’s feasible, it may still not be efficient.
Summing up, the direction seems to be “unsupervised learning, using mid-execution feedback / zero failure adaptive behavior where possible”. This does not look too bad to me. (By the way I’m not even sure that in the best (in-flight) form, this goes against testability as argued by Tony. 12c adaptive join methods use a deterministic inflection point calculation that should allow for reproducible tests given identical data.)
Did you notice the word “strategic” in the above quotation? Further down in the same chapter, Tony writes, with respect to SQL Plan Management
Although the CBO strategy is all about adaptability, Oracle, like any other company, has to do something to address the demands of its largest and most vocal customers. Here are the tactical plan stability measures that Oracle has taken to address customer concerns about predictability.
So there we have the strategy vs. tactics opposition. But do we necessarily need to see it like this? In the view I’m suggesting, of supervised vs. unsupervised learning, as long as SQL Plan Management goes “unattended” it is not fundamentally in contradiction to the adaptive features. With 12c SPM Evolve Advisor Task, this would be the case.
One digression before I wrap it up. Tony has another very interesting paragraph, about Graham Wood on frequency of statistics gathering:
In 2012 the Real World Performance team from Oracle did a round-the-world tour to try to dispel some myths about Oracle performance and to educate people about performance management. I attended the Edinburgh seminar and found it very stimulating. One of the most interesting suggestions came from Graham Wood. Graham’s observation was that many of Oracle’s customers gather statistics far too frequently. I want to make it clear that Graham did not say that gathering statistics was only required to prevent execution plan changes, and he most definitely didn’t liken gathering statistics to a game of Russian Roulette! However, Graham’s recommendation does suggest, quite correctly, that there is some risk to gathering statistics and that by doing it less often you can reduce that risk considerably.
The risk of statistics calculation refers to DBA_TAB_COL_STATISTICS.LOW_VALUE and DBA_TAB_COL_STATISTICS.HIGH_VALUE which when increasingly off will lead to increasingly wrong cardinality estimations (imagine having collected statistics at 10 P.M. and loading fresh, time-based data during the night – again read up on Jonathan Lewis’ blog for that topic). Here I must say this suggestion – don’t gather statistics too often – does not seem in line to me with the “general direction”. If I’m to trust Oracle to achieve good results with the “unsupervised learning approach”, I want to be able to assume this issue to be handled automatically, too – which would mean for Oracle to look into the algorithm related to how HIGH_VALUE and LOW_VALUE are used in cardinality estimation (introduce something like dynamic sampling here? in specific cases?).
So, that was my try on a take on that topic. What do you think? Do you agree with Tony that “we don’t want that”, or do you see value in the “unsupervised learning” approach? Please feel free to leave a comment to share your opinion!