This is my third and last post covering my presentations from last week’s Tech Event, and it’s no doubt the craziest one :-).
Again I had the honour to be invited by my colleague Ludovico Caldara to participate in the cool “Oracle Database Lightning Talks” session. Now, there is a connection to Oracle here, but mainly, as you’ll see, it’s about a Reverend in a Casino.
So, imagine one of your customers calls you. They are going to use Oracle Transparent Data Encryption (TDE) in their main production OLTP database. They are in a bit of panic. Will performance get worse? Much worse?
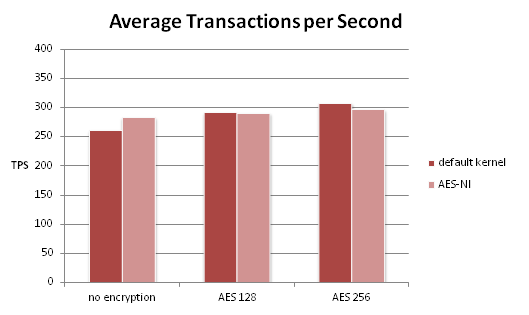
Well, you can help. You perform tests using Swingbench Order Entry benchmark, and soon you can assure them: No problem. The below chart shows average response times for one of the transaction types of Order Entry, using either no encryption or TDE with one of AES-128 or AES-256.
Wait a moment – doesn’t it even look as though response times are even lower with TDE!?

Well, they might be, or they might not be … the Swingbench results include how often a transaction was performed, and the standard deviation … so how about we ask somebody who knows something about statistics?
Cool, but … as you can see, for example, in this xkcd comic, there is no such thing as an average statistician … In short, there’s frequentist statistics and there’s Bayesian, and while there is a whole lot you can say about the respective philosophical backgrounds it mainly boils down to one thing: Bayesians take into account not just the actual data – the sample – but also the prior probability.
This is where the Reverend enters the game . The fundament of Bayesian statistics is Bayes theorem, named after Reverend Thomas Bayes.
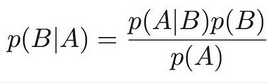
In short, Bayes Theorem says that the probability of a hypothesis, given my measured data (POSTERIOR), is equal to the the probability of the data, given the hypothesis is correct (LIKELIHOOD), times the prior probability of the hypothesis (PRIOR), divided by the overall probability of the data (EVIDENCE). (The evidence may be neglected if we’re interested in proportionality only, not equality.)
So … why should we care? Well, from what we know how TDE works, it cannot possibly make things faster! In the best case, we’re servicing all requests from the buffer cache and so, do not have to decrypt the data. Then we shouldn’t incur any performance loss. But I cannot imagine how TDE could cause a performance boost.
So we go to our colleague the Bayesian statistian, give him our data and tell him about our prior beliefs.(Prior belief sounds subjective? It is, but prior assumptions are out in the open, to be questioned, discussed and justified.).
Now harmless as Bayes theorem looks, in practice it may be difficult to compute the posterior probability. Fortunately, there is a solution:Markov Chain Monte Carlo (MCMC). MCMC is a method to obtain the parameters of the posterior distribution not by calculating them directly, but by sampling, performing a random walk along the posterior distribution.
We assume our data is gamma distributed, the gamma distribution generally being adequate for response time data (for motivation and background, see chapter 3.5 of Analyzing Computer System Performance with Perl::PDQ by Neil Gunther).
Using R, JAGS (Just Another Gibbs Sampler), and rjags, we (oh, our colleague the statistian I meant, of course) go to work and create a model for the likelihood and the prior.
We have two groups, TDE and “no encryption”. For both, we define a gamma likelihood function, each having its own shape and rate parameters. (Shape and rate parameters can easily be calculated from mean and standard deviation.)
model {
for ( i in 1:Ntotal ) {
y[i] ~ dgamma( sh[x[i]] , ra[x[i]] )
}
sh[1] <- pow(m[1],2) / pow(sd[1],2)
sh[2] <- pow(m[2],2) / pow(sd[2],2)
ra[1] <- m[1] / pow(sd[1],2)
ra[2] <- m[2] / pow(sd[2],2
[...]
Second, we define prior distributions on the means and standard deviations of the likelihood functions:
[...]
m[1] ~ dgamma(priorSha1, priorRa1)
m[2] ~ dgamma(priorSha2, priorRa2)
sd[1] ~ dunif(0,100)
sd[2] ~ dunif(0,100)
}
As we are convinced that TDE cannot possibly make it run faster, we assume that the means of both likelihood functions are distributed according to prior distributions with the same mean. This mean is calculated from the data, averaging over all response times from both groups. As a consequence, in the above code, priorSha1 = priorSha2 and priorRa1 = priorRa2. On the other hand, we have no prior assumptions about the likelihood functions’ deviations, so we model them as uniformly distributed, choosing noninformative priors.
Now we start our sampler. Faites vos jeux … rien ne va plus … and what do we get?

Here we see the outcome of our random walks, the posterior distributions of means for the two conditions. Clearly, the modes are different. But what to conclude? The means of the two data sets were different too, right?
What we need to look at is the distribution of the difference of both parameters. What we see here is that the 95% highest density interval (HDI) [3] of the posterior distribution of the difference ranges from -0.69 to +1.89, and thus, includes 0. (HDI is a concept similar, but superior to the classical frequentist confidence interval, as it is composed of the 95% values with the highest probability.)
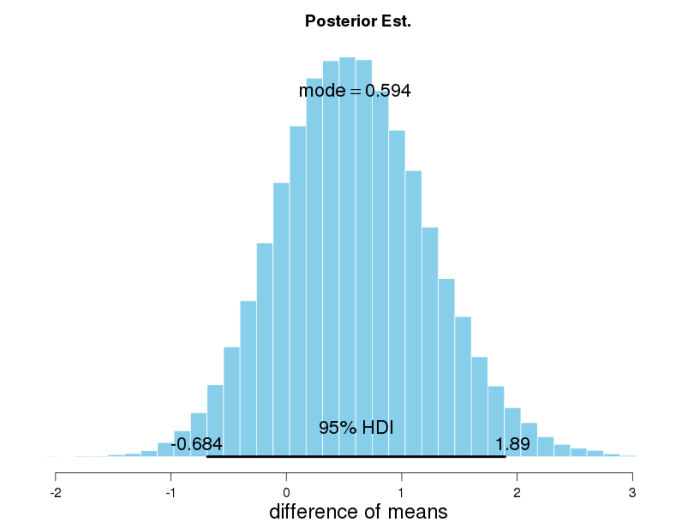
From this we conclude that statistically, our observed difference of means is not significant – what a shame. Wouldn’t it have been nice if we could speed up our app using TDE 😉