R for SQListas, part 2
Welcome to part 2 of my “R for SQListas” series. Last time, it was all about how to get started with R if you’re a SQL girl (or guy)- and that basically meant an introduction to Hadley Wickham’s dplyr and the tidyverse. The logic being: Don’t fear, it’s not that different from what you’re used to.
This (and upcoming) times it will be about the other side of the coin – if R was “basically just like SQL”, why not stick with SQL in the first place?
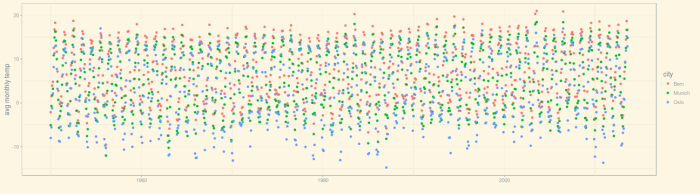
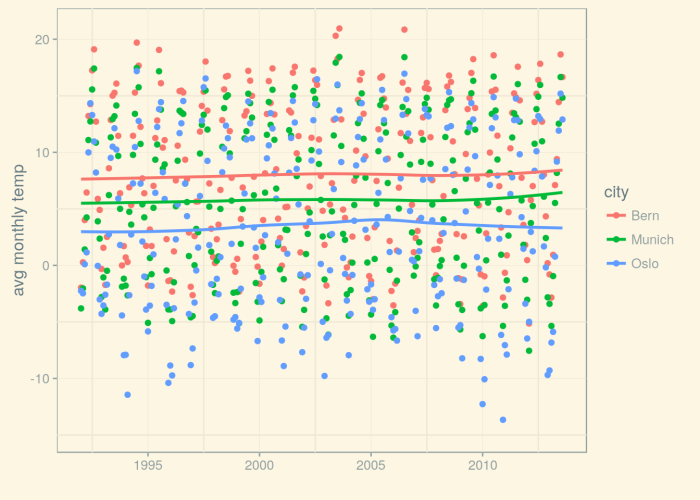
So now, it’s about things you cannot do with SQL, things R excels at – those things you’re learning R for :-). Remember in the last post, I said I was interested in future developments of weather/climate, and we explored the Kaggle Earth dataset (as well as another one, daily data measured at weather station Munich airport)? In this post, we’ll finally try to find out what’s going to happen to future winters. We’ll go beyond adding trend lines to measurements, and do some real time series analysis!
Inspecting the time series
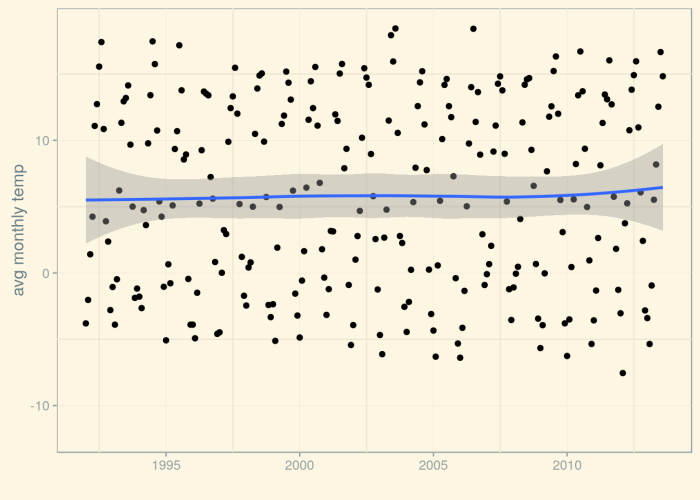
First, we create a time series object from the dataframe and plot it – time series objects have their own plot() methods:
start_time <- as.Date("1992-01-01")
ts_1950 <- ts(df_munich$avg_temp, start = c(1950,1), end=c(2013,8), frequency = 12)

Time series decomposition
Now, let’s decompose the time series into its components: trend, seasonal effect, and remainder. We clearly expect there to be seasonality – the influence of the month we’re in should be clearly visible – but as stated before we’re mostly interested in the trend.
fit1 <- stlplus(ts_1950, s.window="periodic")
fit2 <- stlplus(ts_1992, s.window="periodic")
grid.arrange(plot(fit1), plot(fit2), ncol = 2)
The third row is the trend. Basically, there seems to be no trend – no long-term changes in the temperature level. However, by default, the trend displayed is rather „wiggly“.

We can experiment with different settings for the smoothing window of the trend. Let‘s use two different degrees of smoothing, both more „flattening“ than the default:
fit1 <- stlplus(ts_1950, s.window="periodic", t.window=37)
fit2 <- stlplus(ts_1950, s.window="periodic", t.window=51)
grid.arrange(plot(fit1), plot(fit2), ncol = 2, top = 'Time series decomposition, 1950 - 2013')

From these decompositions, it does not seem like there’s a significant trend. Let’s see if we can corroborate the visual impression by some statistical data. Let’s forecast the weather!
We will use two prominent approaches in time series modeling/forecasting: exponential smoothing and ARIMA.
Exponential smoothing
With exponential smoothing, the value at each point in time is basically seen as a weighted average, where more distant points weigh less and nearer points weigh more. In the simplest realization, a value at time t(n+1) is modeled as weighted average of the value at time t and the incoming observation at time t(n+1):

More complex models exist that factor in trends and seasonal effects.
For our case of a model with both trend and seasonal effects, the Holt-Winters exponential smoothing method generates point forecasts. Equivalently (conceptually that is, not implementation-wise; see http://robjhyndman.com/hyndsight/estimation2/), we can use the State Space Model (http://www.exponentialsmoothing.net/) that additionally generates prediction intervals.
The State Space Model is implemented in R by the ets() function in the forecast package. When we call ets() without any parameters, the method will determine a suitable model using maximum likelihood estimation. Let’s see the model chosen by ets():
fit <- ets(ts_1950)
summary(fit)
## ETS(A,N,A)
##
## Call:
## ets(y = ts_1950)
##
## Smoothing parameters:
## alpha = 0.0202
## gamma = 1e-04
##
## Initial states:
## l = 5.3364
## s=-8.3652 -4.6693 0.7114 5.4325 8.8662 9.3076
## 7.3288 4.1447 -0.677 -4.3463 -8.2749 -9.4586
##
## sigma: 1.7217
##
## AIC AICc BIC
## 5932.003 5932.644 6001.581
##
## Training set error measures:
## ME RMSE MAE MPE MAPE MASE
## Training set 0.02606379 1.72165 1.345745 22.85555 103.3956 0.7208272
## ACF1
## Training set 0.09684748
The model chosen does not contain a smoothing parameter for the trend (beta) – in fact, it is an A,N,A model, which is the acronym for Additive errors, No trend, Additive seasonal effects.
Let’s inspect the decomposition corresponding to this model – there is no trend line here:
plot(fit)

Now, let’s forecast the next 36 months!
plot(forecast(fit, h=36))

The forecasts look rather „shrunken to the mean“, and the prediction intervals – dark grey indicates the 95%, light grey the 80% prediction interval – seem rather narrow. Indeed, narrow prediction intervals are often a problem with time series, because there are many sources of error that aren’t factored in the model (see http://robjhyndman.com/hyndsight/narrow-pi/).
ARIMA
The second approach to forecasting we will use is ARIMA. With ARIMA, there are three important concepts:
-
AR(p): If a process is autoregressive, future values are obtained as linear combinations of past values, i.e.

where e is white noise. A process that uses values from up to p time points back is called an AR(p) process.
-
I(d):This refers to the number of times differencing (= subtraction of consecutive values) has to be applied to obtain a stationary series.
If a time series yt is stationary, then for all s, the distribution of (y(t),…, y(t+s)) does not depend on t. Stationarity can be determined visually, inspecting the autocorrelation and partial autocorrelation functions, as well as using statistical tests. -
MA(q): An MA(q) process combines past forecast errors from time points up to p times back to forecast the current value:

While we can feed R’s Arima() function with our assumptions about the parameters (from data exploration or prior knowledge), there’s also auto.arima() which will determine the parameters for us.
Before calling auto.arima() though, let’s inspect the autocorrelation properties of our series. We clearly expect there to be autocorrelation – for one, adjacent months are similar in temperature, and second, we have similar temperatures every 12 months.
tsdisplay(ts_1950)

So we clearly see that temperatures for adjacent months are positively correlated, while months in „opposite“ seasons are negatively correlated. The partial autocorrelations (where correlations at lower lags are controlled for) are quite strong, too. Does this mean the series is non-stationary?
Not really. A seasonal series of temperatures can be seen as a cyclostationary process (https://en.wikipedia.org/wiki/Cyclostationary_process) , where mean and variance are constant for seasonally corresponding measurements. We can check for stationarity using a statistical test, too:
adf.test(ts_1950)
##
## Augmented Dickey-Fuller Test
##
## data: ts_1950
## Dickey-Fuller = -11.121, Lag order = 9, p-value = 0.01
## alternative hypothesis: stationary
According to the Augmented Dickey-Fuller test, the null hypothesis onf non-stationarity should be rejected.
So now let’s run auto.arima on our time series.
fit <- auto.arima(ts_1950)
summary(fit)
## Series: ts_1950
## ARIMA(1,0,5)(0,0,2)[12] with non-zero mean
##
## Coefficients:
## ar1 ma1 ma2 ma3 ma4 ma5 sma1 sma2
## 0.6895 -0.0794 -0.0408 -0.1266 -0.3003 -0.2461 0.3972 0.3555
## s.e. 0.0409 0.0535 0.0346 0.0389 0.0370 0.0347 0.0413 0.0342
## intercept
## 5.1667
## s.e. 0.1137
##
## sigma^2 estimated as 7.242: log likelihood=-1838.47
## AIC=3696.94 AICc=3697.24 BIC=3743.33
##
## Training set error measures:
## ME RMSE MAE MPE MAPE MASE
## Training set -0.001132392 2.675279 2.121494 23.30576 116.9652 1.136345
## ACF1
## Training set 0.03740769
The model chosen by auto.arima is ARIMA(1,0,5)(0,0,2)[12] where the first triple of parameters refers to the non-seasonal part of ARIMA, the second to the seasonal one, and the subscript designates seasonality (12 in our case). So in both parts, no differences are applied (d=0). The non-seasonal part has an autoregressive and a moving average component, the seasonal one is moving average only.
Now, let’s get forecasting! Well, not so fast. ARIMA forecasts are based on the assumption that the residuals (errors) are uncorrelated and normally distributed. Let’s check this:
res <- fit$residuals
acf(res)
While normality of the errors is not a problem here, the ACF does not look good:

Clearly, the errors are not uncorrelated over time. We can improve auto.arima performance (at the cost of prolonged runtime) by allowing for a higher maximum number of parameters (max.order, which by default equals 5) and setting stepwise=FALSE:
fit <- auto.arima(ts_1950, max.order = 10, stepwise=FALSE)
summary(fit)
## Series: ts_1950
## ARIMA(5,0,1)(0,0,2)[12] with non-zero mean
##
## Coefficients:
## ar1 ar2 ar3 ar4 ar5 ma1 sma1 sma2
## 0.8397 -0.0588 -0.0691 -0.2087 -0.2071 -0.4538 0.0869 0.1422
## s.e. 0.0531 0.0516 0.0471 0.0462 0.0436 0.0437 0.0368 0.0371
## intercept
## 5.1709
## s.e. 0.0701
##
## sigma^2 estimated as 4.182: log likelihood=-1629.11
## AIC=3278.22 AICc=3278.51 BIC=3324.61
##
## Training set error measures:
## ME RMSE MAE MPE MAPE MASE
## Training set -0.003793625 2.033009 1.607367 -0.2079903 110.0913 0.8609609
## ACF1
## Training set -0.0228192
The less constrained model indeed performs better (judging by AIC, which drops from to 3696 to 3278). Autocorrelation of errors also is reduced overall.
Now, with the improved models, let’s finally get forecasting!
fit <- auto.arima(ts_1997, stepwise=FALSE, max.order = 10)
summary(fit)

Comparing this forecast with that from exponential smoothing, we see that exponential smoothing seems to deal better with smaller training samples, as well as with longer extrapolation periods.
Now we could go on and use still more sophisticated methods, or use hybrid models that combine different forecast methods, analogously to random forests, or even use deep learning – but I’ll leave that for another time 🙂 Thanks for reading!